Transportando datos de archivos de texto plano a tablas de SQL Server con BizTalk Server 2006 paso a paso. Parte 1 de 2
No es raro hoy en día encontrarnos con aplicaciones que integran datos de diferentes plataformas para obtener la información necesaria y poder explotarla adecuadamente. Son bastantes los escenarios que nos podemos encontrar como consultores en los que determinada empresa cuenta ya con un sistema de tipo legacy y que debido a su gran importancia histórica es imposible tirarlo a la basura incluso resultaría bastante caro y arriesgado adentrarse en el largo y sinuoso camino de la migración total -incluso parcial- de su código a una plataforma moderna y escalable como es .NET. Por lo anterior es muy común que las empresas requieran de alguna forma u otra seguir obteniendo o procesando los datos que sus sistemas legacy arrojan y a la vez renovar su plataforma y arquitectura tecnológica a nuevos horizontes.
Así que, en este artículo aprenderemos a procesar archivos de texto planos para leer su contenido y posteriormente escribirlo a tablas de SQL Server 2005 por medio de una orquestación de BizTalk Server 2006. Una vez terminado de leer este artículo podrán apreciar lo sencillo que puede ser esta tarea al ser coordinada y procesada con esta magnífica pieza de software.
El escenario
Nuestro sistema legacy es un sistema de compras e inventarios de una cadena de gran importancia a nivel nacional de venta de discos compactos musicales. No obstante, la empresa requiere que el catálogo de discos sea replicado a una base de datos de SQL Server 2005 por medio de una orquestación de BizTalk Server 2006 una vez que un nuevo título llegue a su inventario.
El sistema legacy escribirá un archivo de texto plano con extensión .txt por artista una vez que nuevos álbumes lleguen al inventario. El archivo de texto plano tendrá el siguiente esquema:
ARTISTAID | NOMBRE | GENERO
ARTISTAID | ALBUMID | TITULO_DEL_ALBUM | ANIO | CANTIDAD
ARTISTAID | ALBUMID | TITULO_DEL_ALBUM | ANIO | CANTIDAD
ARTISTAID | ALBUMID | TITULO_DEL_ALBUM | ANIO | CANTIDAD
…
Con lo anterior podemos deducir que en un solo archivo podrán incluirse diferentes albumes del mismo artista. Además, podemos observar que los archivos incluyen el pipe (|) como separador de cada atributo.
Por otro lado, tenemos una base de datos de SQL Server 2005 llamada Tienda la cual cuenta con las tablas Artista y Album que son donde se depositarán los datos de los archivos de texto plano y su esquema es el siguiente:
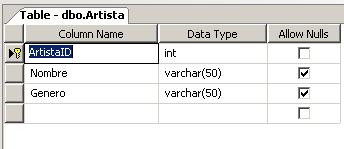
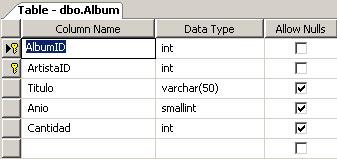
La solución
La solución está basada en una orquestación implementada con BizTalk Server 2006 la cual será capaz de detectar la existencia de un nuevo archivo y procesará su contenido apropiadamente para escribir los datos en las tablas del servidor de SQL Server 2005.
Para iniciar, implementemos los procedimientos almacenados encargados de escribir los datos en las tablas de la base de datos. Los procedimientos almacenados serán llamados spInsertaArtista y spInsertaAlbum para las tablas Artista y Album respectivamente y su código es el siguiente:
create procedure dbo.InsertaArtista
@ArtistaID int,
@Nombre varchar(50),
@Genero varchar(50)
as
Set nocount on
Insert into Artista (ArtistaID, Nombre, Genero)
Values (@ArtistaID, @Nombre, @Genero)
go
create procedure dbo.InsertaAlbum
@ArtistaID int,
@AlbumID int,
@Titulo varchar(50),
@Anio smallint,
@Cantidad int
as
Set nocount on
Insert into Album
(ArtistaID, AlbumID, Titulo, Anio, Cantidad)
Values
(@ArtistaID, @AlbumID, @Titulo, @Anio, @Cantidad)
También necesitamos un login de SQL para poder conectarnos a SQL Server 2005 desde BizTalk y poder ejecutar los procedimientos almacenados. Claro está que será más recomendable usar autenticación de tipo Windows en vez de usar usuarios de tipo SQL pero para este artículo lo dejaremos así. La cuenta que crearemos será biztalkuser con el password Pa$$W0rd y le asignaremos el rol de dbo_owner sobre la base de datos Tienda:

Muy bien, tenemos los elementos básicos para comenzar. Lo primero que vamos a hacer es abrir Visual Studio .NET y crearemos un nuevo proyecto de tipo Empty BizTalk Server Project y le pondremos el nombre Tienda, tal y como lo muestra la siguiente figura:
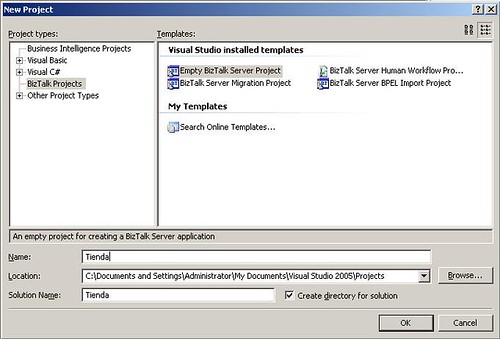
Una vez creado nuestro proyecto es buena idea cambiarle las propiedades Application Name y Restart Host Instances para poder identificar nuestra aplicación en la consola de administración de BizTalk y para reiniciar todas las instancias cuando despleguemos el proyecto respectivamente. La siguiente figura muestra las propiedades de nuestro proyecto:
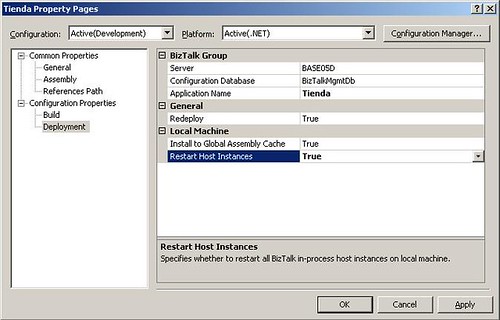
Por efectos de orden y limpieza en nuestro proyecto crearemos los siguientes fólders:
Nombre
Descripción
FFSchema
Aquí guardaremos los esquemas para el pipeline que lee los archivos de texto planos
Map
Aquí guardaremos los mapas de transformación
Pipeline
Aquí guardaremos los pipelines de recepción para los archivos de texto planos
SPSchema
Aquí guardaremos los esquemas necesarios para ejecutar los procedimientos almacenados en SQL Server 2005
Creación de los esquemas
El siguiente paso será la creación de los esquemas apropiados para interpretar el esquema de los archivos de texto plano. Para el tipo de archivo que procesaremos en este ejemplo crearemos dos esquemas: uno para el header que contiene información básica del artista y otro para el detalle el cual como mencionamos anteriormente puede contener uno o varios albumes del mismo artista. Los siguientes pasos muestran la creación del esquema para los álbumes, sin embargo serán los mismos pasos para la creación del esquema para el artista. Para hacer esto agreguemos al fólder FFSchema un nuevo elemento de tipo Flat File Schema Wizard y asignemos el nombre Tienda_Album.xsd tal como lo muestra la siguiente figura
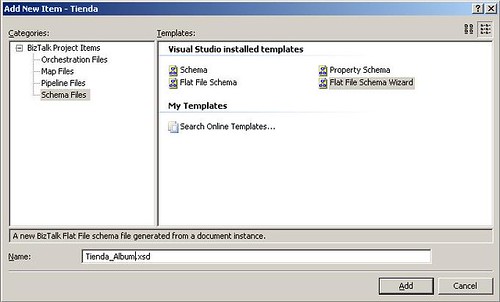
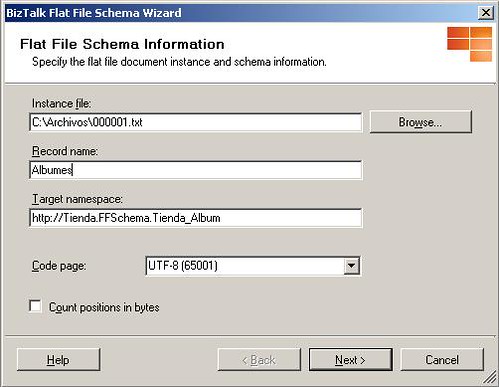
Al hacer anterior Visual Studio nos muestra el asistente de creación de esquemas para archivos de texto planos. En la primer ventana asignaremos un archivo muestra de los cuales necesitamos procesar y asignaremos algunos parámetros como Record name y Target namespace. La siguiente figura da ejemplo de esto:
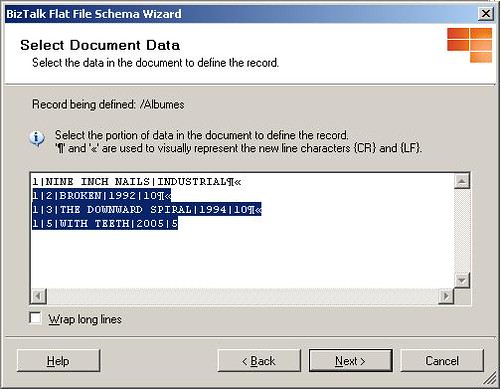
La siguiente tarea será seleccionar las líneas en el archivo de texto que representan el detalle tal y como lo muestra la siguiente figura:
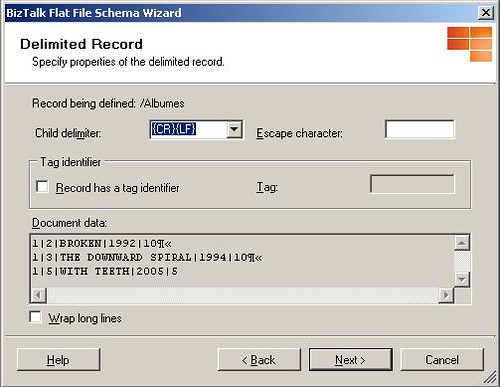
Hagamos clic en siguiente para aceptar la opción "By delimiter symbol". La siguiente ventana nos solicita indicar el delimitador para cada registro, en nuestro caso será el default {CR}{LF} ya que cada registro está indicado en una línea por separado. La siguiente figura muestra esta ventana:
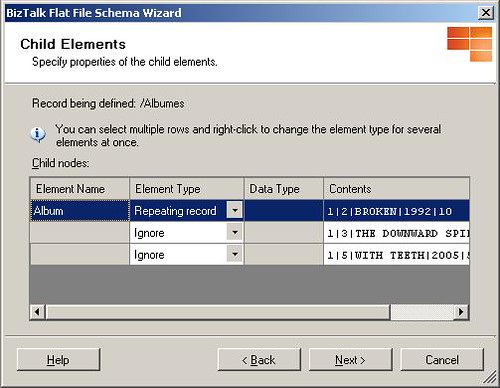
Al hacer clic en el botón Siguiente en la ventana anterior se nos muestra la opción de indicar cuáles son los elementos hijos. En el caso específico de este ejemplo seleccionaremos el primer registro como Repeating record y le asignaremos el nombre Album mientras que al resto de registros les asignaremos el tipo Ignore ya que son exactamente iguales que el primero en estructura. La siguiente figura muestra los elementos configurados:
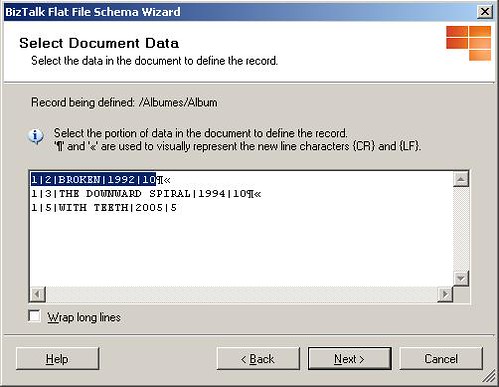
La siguiente ventana nos muestra un resumen del esquema, sin embargo aun falta terminar de configurar los registros así que haremos clic en siguiente. La siguiente ventana llamada "Select Document Data" nos solicita seleccionar los datos que definen un registro dentro del archivo de texto plano. De manera predeterminada el asistente es lo suficientemente inteligente para seleccionar el registro tal como lo muestra la siguiente figura, posteriormente haremos clic en Siguiente.
Tal y como hicimos anteriormente, en la ventana "Select Record Format" aceptaremos la opción "By delimiter symbol" y haremos clic en el botón Next.
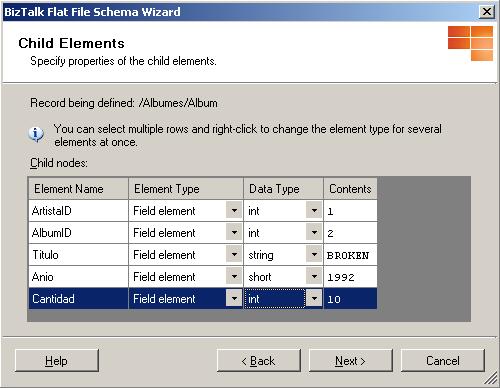
Ahora se nos presenta de nueva cuenta la ventana "Delimited Record", en ella especificaremos en la lista desplegable llamada "Child delimiter" el caracter que delimita cada columna dentro de nuestro archivo en este caso se trata del pipe (|). Al hacer clic en el botón Next se nos muestra la siguiente ventana en donde podemos definir el nombre de cada elemento (columna) que representa un registro de cada álbum:
Al hacer clic en siguiente se nos presenta el resumen del esquema y para terminar haremos clic en el botón Finish.
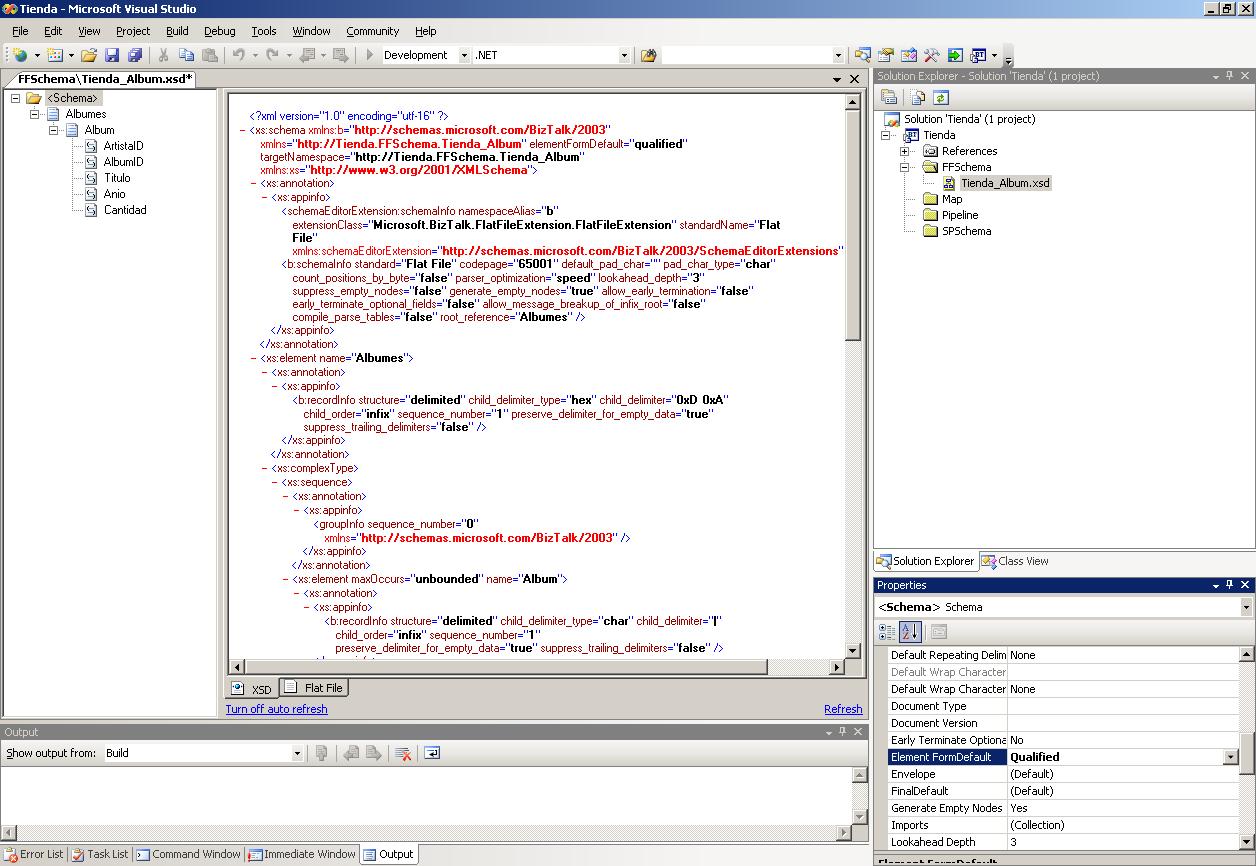
Una vez terminada la creación del esquema modificaremos la propiedad Element FormDefault del nodo <Schema> para tener el valor "Qualified":
No olvidemos el esquema para el Artista! Sigamos todos los pasos anteriores que usamos para crear el esquema de los álbumes con la única diferencia que a la propiedad Max Occurs en Artistas/Artista le asignaremos un valor de 1.
Creación del Pipeline de recepción
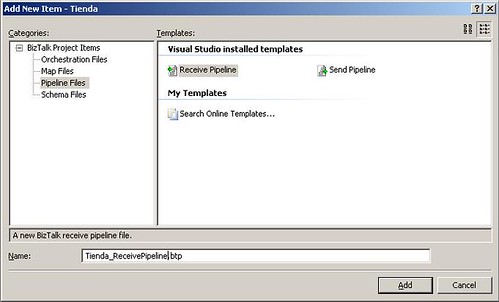
Nuestra siguiente tarea será la creación del pipeline de recepción para nuestro proyecto. Para hacer esto agreguemos un nuevo elemento de tipo Receive Pipeline dentro de nuestro fólder Pipeline y asignemos el nombre Tienda_ReceivePipeline.btp tal como lo muestra la siguiente figura:
Para diseñar nuestro pipeline usaremos el componente Flat file disassembler y lo colocaremos en la sección "Disassemble" del diseñador la cual permite indicar la funcionalidad a ejecutar cuando queremos desensamblar nuestro archivo. Además le asignaremos las propiedades Document schema y Header schema a Tienda_Album y Tienda_Artista respectivamente, además de poner en True la propiedad Preserve header. La siguiente figura muestra el componente Flat file dissasembler configurado:

Wuf! Vamos muy bien pero aún falta camino por recorrer. La segunda parte de este articulo explicará la orquestación de BizTalk y demostrará cómo todas las piezas de este rompecabezas se unen.